In the first half of this article, we set up an EC2 instance on Amazon AWS, deployed our LAMP-based micro-site on it, tested it, and created an AMI image of the web application. If you’re following along and have an EC2/AMI ready, continue below to configure auto-scaling, otherwise review Part 1.
Within the overall umbrella of Amazon Web Services are dozens of individual technologies that you can use together to provision, launch, monitor and manage scalable web applications. Setting up intelligent auto scaling (AS) on AWS requires several of them, including:
Online marketers spend hours, days, weeks and even months, planning marketing campaigns, both online and offline, to drive traffic to websites, and IT provisioning is difficult even when you know in advance when the traffic is coming. But what if you don’t know when a huge traffic spike will hit your server? The better a social or viral marketing campaign is, the more likely it could result in irregular traffic patterns or server load spikes at unexpected times. The flexibility of AWS autoscaling frees you from having to accurately predict and provision servers in advance of huge traffic spikes.
In general, Auto scaling with Amazon Web Services works like this:
That’s the toughest question to answer—a lot of variable factors are involved. It depends on the volume of traffic you receive, the type of EC2 instances you use, and the complexity of your application. For our simple PHP application, we estimated that a single t1.micro instance, Amazon’s smallest and least expensive EC2 option, should easily handle between 50 to 75 simultaneous users. We determined this based on the available amount of RAM available in a t1.micro instance, and comparing that to the average amount of memory taken by a typical PHP request on our application. We then did some actual load-testing and benchmarking with the command-line tool, siege. We’ll get into the details of that later. Ultimately we decided that we wanted no fewer than 2 servers and no more than 100, or support for up to 7,500 simultaneous users, based on using t1.micro’s in our autoscaling configuration.
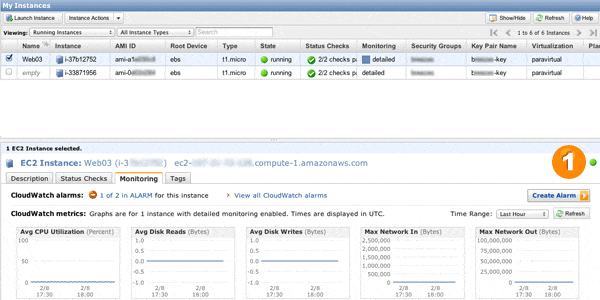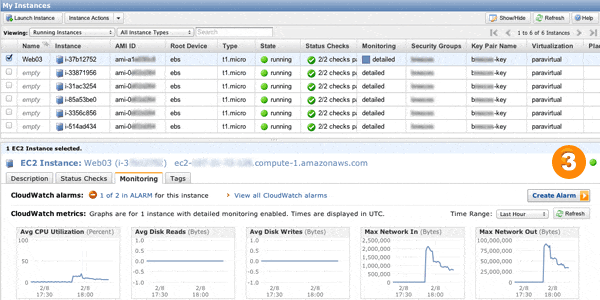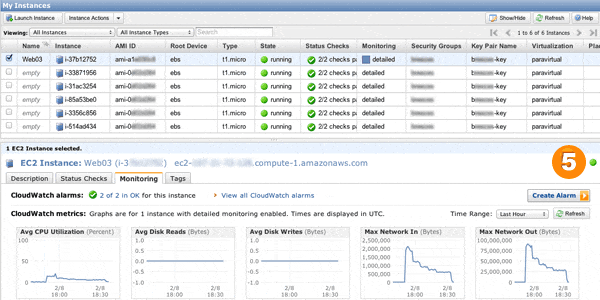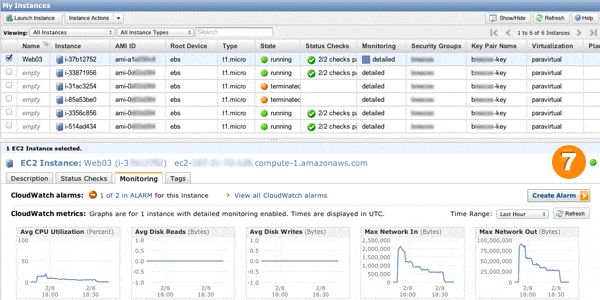
AWS CloudWatch lets you monitor several different EC2 server performance metrics in real time, including…
…and many more. It’s up to you what to monitor, but the metrics most useful for knowing when you should scale up and add another server or scale down by terminating a server are probably CPU utilization, memory utilization or network utilization.
It should also be noted that Amazon provides plenty of basic monitoring metrics for free. Basic monitoring has a 5 minute refresh interval. If monitoring every 5 minutes isn’t fast enough for your application, you can also look at the detailed monitoring option, which costs only fifty cents per metric per month. Detailed monitoring fires events at 1-minute intervals. Here’s a list of the EC2 metrics you can monitor using CloudWatch. If you don’t find a metric that will suit your application, you can even submit (via the Amazon AWS API) a custom metric from your app that CloudWatch should monitor.
Before we get started, let’s look at the two prerequisites you need to have in place before creating an auto scaling configuration.
Prerequisite 1: Choose an AMI to use. If you haven’t created an AMI from one of your running EC2 instances, go back to Part 1 and create an AMI now, or click over to your AMIs page on the AWS Console to retrieve the AMI ID to be used as a template, and write it down. You’ll need an AMI ID in Step 1.
Prerequisite 2: Fire up an ELB. The ELB name that is displayed on the AWS Console will also be passed to the command we run in Step 2. We used the AWS Console to create an ELB, and simply accepted the defaults on each of the Elastic Load Balancer setup screens. Once your ELB is up, you will most likely create a CNAME record at your DNS provider pointing your landing page or vanity domain to the DNS name given in the AWS Console. Visit the Elastic Load Balancing at Amazon AWS page for additional information.
Okay, here we go! As we mentioned above, not all of the functions needed to implement autoscale are implemented in the AWS Management Console yet. So, roll up your sleeves and fire up Terminal (Mac) or CMD (Windows). We’ll be using a few different command line tools to finish our autos caling configuration.
Step 1: Create a launch config. The first command to setting up autoscale is as-create-launch-config. Using this command, you tell AWS:
The API replies with: “OK-Created launch config.”
$PROMPT> as-create-launch-config {your_launch_config_name} --image-id {your_ami_id} --instance-type t1.micro --key {your_access_key} --group {your_group_name}
Return message: OK-Created launch config Step 2: Create an auto scaling group. Use the as-create-auto-scaling-group command to define the properties for your group of servers. Auto scaling groups are the core component of an auto-scaling configuration. This command takes the launch_config_name you defined from the step before as a parameter, the name of the ELB you want to use, and most importantly, lets you define the minimum and maximum number of servers you want to have in your cluster. In the example below, we define a group with a minimum of 2 servers and a maximum of 10.
$PROMPT> as-create-auto-scaling-group {your_scaling_group_name} --launch-configuration {your_launch_config_name} --availability-zones us-east-1d --min-size 2 --max-size 10 --load-balancers {your_load_blancer_name} --health-check-type ELB --grace-period 300
Return message: OK-Created AutoScalingGroup The grace period is the number of seconds that AWS will wait after an autoscaling event occurs before possibly triggering another autoscaling event. This is an important consideration that prevents AWS from adding too many servers too quickly. AWS responds with “OK-Created AutoScalingGroup.”
Step 3: Create auto scaling policies. Once we have our EC2 AMI, an AS launch config, and an AS group defined to deploy our instances into, we’re ready to define the auto scaling policies that will actually cause more (or fewer) EC2 instances to be launched and attached behind the ELB.
The command used to change the number of servers in the group is the as-put-scaling-policy command. With auto scaling, you use EC2 monitoring within CloudWatch to trigger a certain policy, but before we can do that, we need to define the actual policies that will be triggered. You can use this command to manually trigger scaling events as well, for testing before your traffic burst arrives, and in doing so, you can not only see the effect of scaling up and down, but you can watch AWS work its magic by refreshing your Instances view—new server instances appear in the AWS Management Console as your traffic increases beyond the thresholds you set.
The as-put-scaling-policy command takes the auto scaling group name we defined in step 1, a name for the policy, such a “scale-up” or “scale-down,” the type of scaling change the policy defines, and a cooldown period. Again, the cooldown period is used to prevent AWS from executing multiple policies within a very short time.
$PROMPT> as-put-scaling-policy --auto-scaling-group {your_scaling_group_name} --name scale-up --adjustment 1 --type ChangeInCapacity --cooldown 300
Return message: arn:aws:autoscaling:us-east-1:751374139099:scalingPolicy:e31ae79c-4210-42ad-8d86-60210aaf7a20:autoScalingGroupName/sg-breezes-gma:policyName/scale-up Above you can see the basic upscale policy we defined, named “scale-up,” a ChangeInCapacity policy to add 1 server and wait 3 minutes before another policy can be triggered. Below is the reverse operation, or a “scale-down” policy to remove 1 server from our group.
$PROMPT> as-put-scaling-policy --auto-scaling-group {your_scaling_group_name} --name scale-dn "--adjustment=-1" --type ChangeInCapacity --cooldown 300
Return message: arn:aws:autoscaling:us-east-1:751374139099:scalingPolicy:07a0f71c-d214-4497-973f-c4cdcb15851f:autoScalingGroupName/sg-breezes-gma:policyName/scale-dn
In both cases, AWS replies with a return message including the unique auto-generated name of our two new auto scaling policies. We’ll use those unique policy identifiers to connect to our CloudWatch events in the final step.
Step 4: Link a CloudWatch event to an auto scaling policy. At the moment we have everything we need for an intelligent autoscaling configuration except one thing—the intelligence! The smarts come from choosing a CloudWatch event, such as 80% CPU utilization of an EC2 instance in our group, and wiring up that condition to automatically trigger the scale-up policy we defined. We’re also going to want to do the same in reverse for scaling back down at 20% CPU utilization.
The command to do this comes from the CloudWatch command line tools, and is called mon-put-metric-alarm. This command takes several parameters:
As you can see, there’s a lot to this command, but once we look at every parameter, you can see that without each of them, you wouldn’t have the ability to control auto scaling changes with enough granularity. The name and description are shown back to you later when using the mon-describe-alarms command. The statistics you’re watching, and the thresholds and time intervals, are important to test for your particular application. For example, we chose to monitor average CPU utilization for a period of 60 seconds, and an evaluation period of 3 intervals (or 3 minutes), for an event of 80% or greater level. Here’s the command to achieve this.
$PROMPT> mon-put-metric-alarm --alarm-name sample-scale-up --alarm-description "Scale up at 80% load" --metric-name CPUUtilization --namespace AWS/EC2 --statistic Average --period 60 --threshold 80 --comparison-operator GreaterThanThreshold --dimensions InstanceId=i-37b12752 --evaluation-periods 3 --unit Percent --alarm-actions arn:aws:autoscaling:us-east-1:751374139099:scalingPolicy:78d05062-0eda-436c-864e-d93776461eba:autoScalingGroupName/sg-sample-group:policyName/scale-up OK-Created Alarm
In English, the above command says, “If the average CPU utilization of instance i-37b12752 is measured at 80% or greater 3 times over 3 minutes, then trigger our scale-up policy.”
Here is the reverse mon-put-metric-alarm command we used to terminate one of the servers if the CPU utilization drops below an average of 20% over 3 minutes.
$PROMPT> mon-put-metric-alarm --alarm-name sample-scale-dn --alarm-description "Scale down at 20% load" --metric-name CPUUtilization --namespace AWS/EC2 --statistic Average --period 60 --threshold 20 --comparison-operator LessThanThreshold --dimensions InstanceId=i-37b12752 --evaluation-periods 3 --unit Percent --alarm-actions arn:aws:autoscaling:us-east-1:751374139099:scalingPolicy:78d05062-0eda-436c-864e-d93776461eba:autoScalingGroupName/sg-sample-group:policyName/scale-dn
For more information and examples, refer to the Auto Scaling section on the Amazon developer documentation.
As mentioned above, we used the command line tool siege to work through the configuration setup and to verify whether our policies were working as we wanted. Using siege on a different server or EC2 instance, you can easily simulate tons of website traffic for a short period of time. Siege does this by creating dozens or even hundreds of concurrent HTTP requests to your URL for the duration you specify. This gives you a chance to see what will happen to your auto scaling policies when real users flood your web server with traffic and CloudWatch alarms start triggering.
Siege can be installed with the package manager on your system. We simply ran
sudo apt-get install siege
on our Ubuntu/Debian system, and that was it. TechRepublic.com has a great article on installing from source and using siege.
Siege is simple to use—just give it the number of concurrent connections you want to create (-c), the length of time (-t) to run the test, and your URL, as shown:
siege -c25 -t10M www.example.com
One thing to note here is that CloudWatch basic monitoring refreshes every 5 minutes, and our auto scaling policies above require a metric to be met for 3 consecutive minutes, so we had to run siege tests for at least 6 to 10 minutes to ensure that our policies had enough time to trigger at least twice. While siege was running, we refreshed the CloudWatch tab in AWS Management Console to verify that more servers were indeed getting launched.
It should have come as no surprise that we would need to make changes to our landing page and micro-site at the last minute, right before our client’s scheduled appearance on a national TV show. To make changes to the landing page, we need to upload some new files to our EC2 instance. No big deal, right?
Under a normal web hosting scenario, this is no problem, but when you have an AMI defined to be the source template for an auto scaling configuration, and the entire micro-site content is baked into the AMI, it’s an issue because the moment one of our events is triggered and CloudWatch triggers our auto scaling policy to launch a new instance, it’s going to be copied from our now-stale AMI with the outdated content.
It’d be nice to simply create a new AMI with the changes and re-run the as-create-launch-config script where we define the AMI to use, however trying that gives the following error:
configuration already exists with the name sample-launch-config-name
So that won’t work. Next, we thought maybe could just delete the auto scaling group, using the as-delete-auto-scaling-group command, and AWS asks, “Are you sure you want to delete this AutoScalingGroup?” When we replied “Y,” we got this error:
as-delete-auto-scaling-group: Malformed input-You cannot delete an AutoScalingGroup while there are instances still in the group.
Well that’s good to know—you cannot inadvertently delete an auto scaling group while instances are running inside it. What instances are running inside it? You can use the as-describe-auto-scaling-instances command for that. This command is nearly identical to ec2-describe-instances, but instead of showing all your instances, it lists the ones running inside each autoscaling group you have configured.
In order to actually terminate the instances, though, we have to change the minimum number of instances allowed. Remember, when we ran the as-put-scaling-policy earlier, we defined minimum instances as two. If we terminate the instances in the group, AWS will just launch more to replace them to meet the minimum. So, next, we had to change the minimum number of servers in our auto scaling group to zero. This is most easily done with the as-update-auto-scaling-group command, as shown:
$PROMPT> as-update-auto-scaling-group sample-sg-name --min-size 0 OK-Updated AutoScalingGroup
Once we did that, we could terminate our instances using the as-terminate-instance-in-auto-scaling-group command. Finally, we could run as-delete-auto-scaling-group followed by as-delete-launch-config.
Granted, this manual work to build up and tear down an auto scaling configuration is kind of a pain point, but in our case we didn’t have time to use a proper deployment script, as is normally the case for cloud deployments. On the other hand, it did force us to learn all the command line tools to reverse, undo, tear down and delete an auto scaling configuration and document them here.
To build up an auto scaling group
To tear down an auto scaling group
We have seen tremendous evolution in the server paradigm, with web-based architectures maturing into service orientations before finally evolving into true cloud-based architectures. Today, containers represent the next shift. Check out the latest on the Google Container Engine here.
Our team is heading to San Francisco March 3-5 for RampUp 2026. We'll be meeting…
The rise of browser-based Opt-Out Preference Signals (yes, OOPS) is quietly reshaping online consent experiences.…
We’re thrilled to announce that Merkle Americas has officially agreed to become the platform’s first-ever…
This website uses cookies.
{kind=link}